High Availability is Not Disaster Recovery: Why Your Business Needs Both
Table of contents
- What Is High Availability and How Does It Work?
- What High Availability Protects Against
- What Is Disaster Recovery and Why Is It Different?
- Key DR Concepts: RTO, RPO, and MTD
- High Availability vs Disaster Recovery: The Critical Differences
- Why Businesses Need Both HA and DR Strategies
- Real-World Scenario: When HA Isn’t Enough
- The HA + DR Integration Model
- Comparing Failover Systems: Clustering vs Replication
- DR Site Options: Cold, Warm, and Hot Sites Explained
- Business Continuity: Integrating HA and DR
- Creating Your HA + DR Strategy
- Common Pitfalls to Avoid
- Measuring Success: Key Metrics and Testing
- The Cost of Getting It Wrong
- Conclusion: Complementary Strategies for Complete Protection
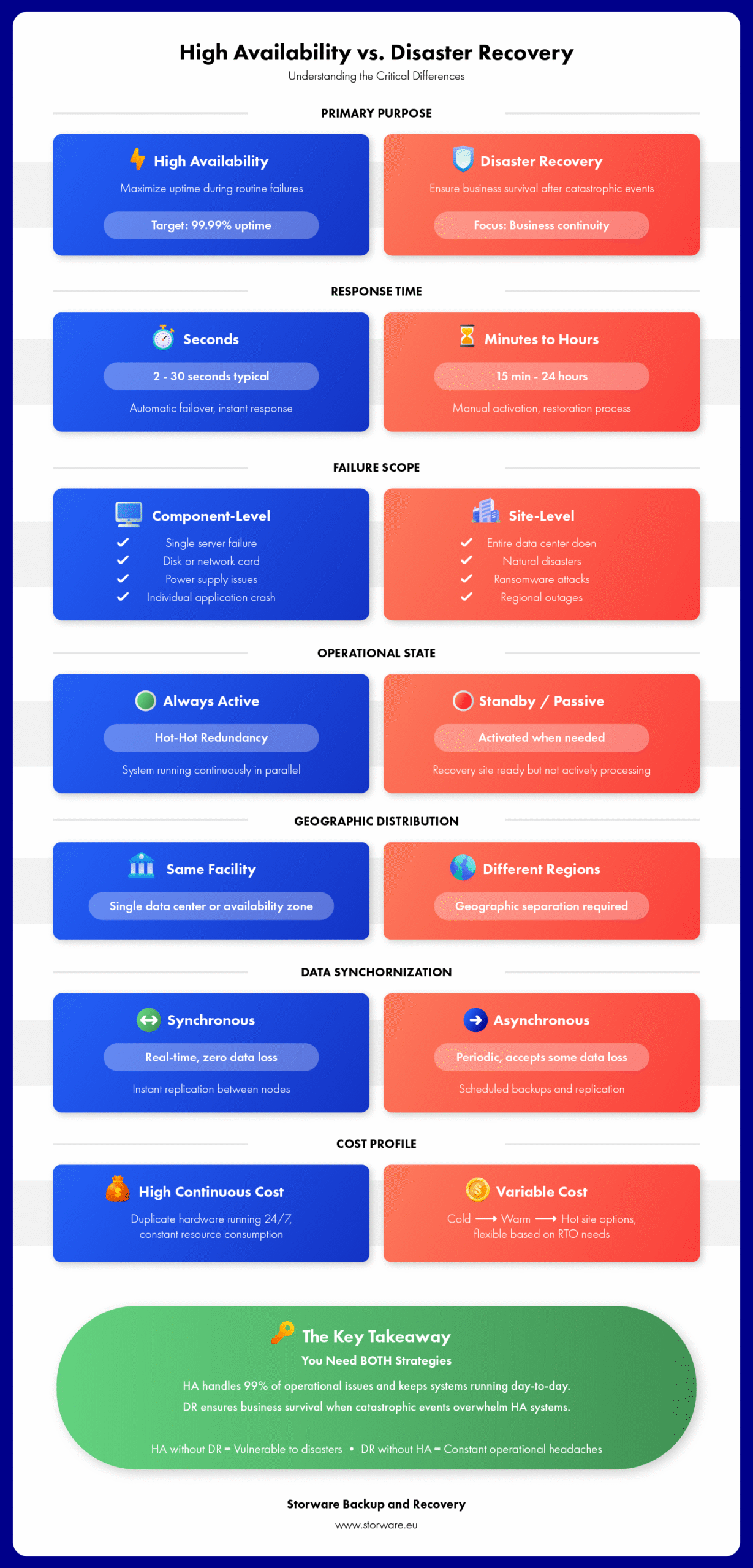
There’s a growing misconception these days: “We have high availability, so we’re protected against disasters.” This conflation of high availability (HA) and disaster recovery (DR) represents one of the most serious gaps in modern business continuity planning. Although both strategies aim to minimize downtime, they address fundamentally different scenarios, operate within different timeframes, and require different technologies and approaches.
For IT professionals responsible for keeping systems running, understanding the difference between high availability and disaster recovery isn’t just technical knowledge—it’s the foundation of comprehensive resilience planning.

What Is High Availability and How Does It Work?
High availability refers to systems designed to operate and be available for as long as possible, typically aiming for 99.9% uptime (8.76 hours of downtime per year) or better. High availability focuses on eliminating single points of failure in the infrastructure through system redundancy and automated failover systems.
Core Components of HA Architecture
A properly designed HA system includes:
- Redundant hardware: Multiple servers, network paths, power supplies, and storage systems
- Load balancing: Distribution of traffic across multiple resources to prevent overload
- Clustering: Multiple servers working together as a single system, with automatic failover
- Real-time replication: Synchronous data mirroring between active nodes
- Health monitoring: Continuous surveillance of system components with automatic failover triggers
- Hot standby systems: Backup components running in parallel, ready to take over instantly
A key characteristic of high availability is speed. In the event of a component failure, HA systems detect the failure within seconds and automatically redirect traffic to redundant resources. Users may experience a brief interruption—often measured in milliseconds—but rarely notice the change.

What High Availability Protects Against
HA excels at handling:
- Single hardware component failures (disk, network card, power supply)
- Individual server crashes or freezes
- Network switch or router failures
- Planned maintenance breaks requiring system updates
- Local power fluctuations or short-term power outages
- Software errors causing service outages
These are everyday operational issues that can cause system failures. High availability ensures applications continue to function despite these “routine” failures, ensuring business continuity with minimal disruption.
What Is Disaster Recovery and Why Is It Different?
Disaster recovery encompasses the strategies, processes, and technologies necessary to restore IT infrastructure and data after a disaster. While HA works in seconds, DR works in minutes or even hours—and covers scenarios in which the entire primary site becomes unavailable.
Understanding Disaster Recovery Scope
DR planning addresses wide-scale failures that render your primary infrastructure unusable:
- Site-wide disasters: Fire, flood, earthquake, or other natural disasters
- Cyber attacks: Ransomware, malware, or coordinated breaches affecting multiple systems
- Data corruption: Application bugs, failed updates, or human errors destroying data integrity
- Loss of entire infrastructure: regional power grid failures, internet service outages, or facility destruction
- Cascading failures: Multiple simultaneous component failures overwhelming HA systems
DR assumes that your primary website, application, or service has been compromised or destroyed. The question isn’t how to keep it running, but how to rebuild and recover it elsewhere.
Key DR Concepts: RTO, RPO, and MTD
Effective disaster recovery planning requires understanding three critical metrics:
Recovery Time Objective (RTO): Maximum tolerable downtime—how long can your business survive without this system? An e-commerce platform might have an RTO of 2 hours; a banking system might require 15 minutes.
Recovery Point Objective (RPO): Maximum acceptable data loss—how much data can you afford to lose? Financial transactions may require an RPO of zero (no data loss); analytics systems might tolerate 24 hours.
Maximum Tolerable Downtime (MTD): The absolute ceiling beyond which business viability is threatened. If your MTD is exceeded, you risk permanent closure, regulatory penalties, or irreparable reputation damage.
High Availability vs Disaster Recovery: The Critical Differences
Let’s take a look at the basic differences through a comprehensive comparison:
Scope of Protection
High Availability: Protects against component-level failures within a single facility. Focuses on infrastructure redundancy and fault tolerance mechanisms within the same data center or availability zone.
Disaster Recovery: Protects against facility-level disasters that can impact an entire facility or geographic region. This requires geographically separated infrastructure and comprehensive data backup strategies.
Response Timeline
HA: Measured in seconds. Automatic failover occurs almost instantaneously through clustering and real-time replication mechanisms.
DR: Measured in minutes or hours, it requires detection, resolution, data recovery, and system validation before service can be restored.
Operational Mode
HA: Always active. Redundant systems operate simultaneously, constantly ready to take on the load.
DR: Typically passive until activated, recovery sites (cold, warm, and hot) exist in various states of readiness, depending on RTO requirements.
Cost Structure
HA: High ongoing operational costs. Hardware duplication, constant synchronization, and active-active configurations constantly consume resources.
DR: Variable costs, depending on strategy. “Cold” sites are inexpensive but slow; “hot” sites are expensive but fast. Most organizations choose “warm” sites as a middle ground.
Primary Goal
HA: Maximize uptime and eliminate user-visible disruptions during routine operational issues
DR: Ensure business survival and disaster recovery.
Why Businesses Need Both HA and DR Strategies
The relationship between high availability and disaster recovery is not an either-or, but ideally a both. These strategies create complementary layers of protection that address different risk categories.
The Reality of Modern Business Operations
Consider a financial services company operating a trading platform:
Without HA: A disk controller failure causes 4 hours of downtime. Cost: $1.2 million in lost transactions, regulatory fines, and reputational damage.
Without DR: A ransomware attack encrypts the entire primary data center. Without multi-site backups, the company is vulnerable to extortion demands or permanent data loss. Cost: Potential company closure.
With HA and DR: Component failures are handled automatically by HA systems. Catastrophic events are resolved using DR procedures. The company maintains resilience in both operational and disaster scenarios.
Real-World Scenario: When HA Isn’t Enough
The retailer invested significantly in high-availability infrastructure:
- Redundant servers with automatic failover
- RAID storage arrays with hot-swappable drives
- Dual power supplies and network connections
- LAs guaranteeing 99.99% availability from their hosting provider
They felt protected. Then ransomware struck.
The attackers not only encrypted one server but also the entire VMware environment, encrypting virtual machines on all hosts in the cluster. The HA systems functioned flawlessly, automatically switching between encrypted systems. Redundancy, which protected against hardware failures, could not protect against a disaster that would have affected the entire infrastructure simultaneously.
Due to the lack of a proper disaster recovery strategy with offline backups and a dedicated recovery site, data recovery took 11 days. The cost: $4.7 million in lost revenue and disaster recovery services.
The HA + DR Integration Model
Optimal business continuity requires integrating both approaches:
Layer 1 – High Availability (Tactical)
- Handles 99% of operational issues
- Automatic, immediate response
- Protects against component failures
- Maintains user experience during routine issues
Layer 2 – Disaster Recovery (Strategic)
- Handles catastrophic failures
- Manual or semi-automated response
- Protects against site-wide disasters
- Ensures business survival when HA is overwhelmed
Together, these layers provide defense-in-depth: HA keeps you running day-to-day, while DR keeps you alive when everything goes wrong.
Comparing Failover Systems: Clustering vs Replication
Understanding the difference between clustering and replication clarifies the HA vs DR distinction further.
Clustering: The HA Approach
Clustering creates a group of servers that function as a single system:
- Nodes share workload and data in real-time
- Failure of one node triggers automatic redistribution to remaining nodes
- Typically within a single data center or close geographic proximity
- Requires high-speed, low-latency network connections
- Provides synchronous data consistency
Example: A three-node database cluster where any node can serve requests. One node fails; the other two immediately absorb its workload without data loss or service interruption.
Replication: The DR Foundation
Replication copies data to geographically separate locations:
- Primary site handles active workload
- Secondary site receives periodic or continuous data updates
- Can tolerate higher latency between sites
- May involve asynchronous data transfer (accepting some potential data loss)
- Requires activation process to promote secondary to primary
Example: Production database in New York replicates to a secondary site in California every 15 minutes. A disaster in New York requires failing over to California, accepting up to 15 minutes of data loss (RPO) and 30-60 minutes to activate the secondary site (RTO).
Modern Hybrid Approaches: Many organizations use synchronous replication within HA clusters (for zero data loss during component failures) combined with asynchronous replication to DR sites (for geographic protection with acceptable RPO).
DR Site Options: Cold, Warm, and Hot Sites Explained
Your disaster recovery strategy requires a secondary location to restore operations. Three primary models exist, each with different cost and recovery characteristics:
Cold Site: Lowest Cost, Longest Recovery
A cold site provides facility space with basic infrastructure (power, cooling, network connectivity) but no pre-installed hardware or applications.
Characteristics:
- Physical space reserved and ready
- No equipment or data pre-positioned
- RTO: Days to weeks
- Lowest ongoing cost
- Requires purchasing/shipping equipment during disaster
Best for: Non-critical systems where extended downtime is acceptable, or budget-constrained organizations willing to accept longer recovery times.
Warm Site: Balanced Approach
A warm site includes pre-installed hardware and infrastructure, with data regularly synchronized from production, but systems remain powered down or running in standby mode.
Characteristics:
- Equipment installed and configured
- Data restored from recent backups
- RTO: Hours to days
- Moderate ongoing cost
- Requires activation and data synchronization during disaster
Best for: Most organizations seeking a balance between cost and recovery speed. This represents the sweet spot for many business continuity plans.
Hot Site: Fastest Recovery, Highest Cost
A hot site mirrors your production environment with real-time replication, running continuously and ready to assume workload immediately.
Characteristics:
- Fully operational duplicate environment
- Real-time or near-real-time data synchronization
- RTO: Minutes to hours
- Highest ongoing cost
- Minimal activation time during disaster
Best for: Mission-critical systems where downtime costs exceed hot site expenses. Financial services, healthcare systems, and e-commerce platforms often justify hot site costs.

Business Continuity: Integrating HA and DR
Comprehensive business continuity planning requires orchestrating both high availability and disaster recovery into a unified strategy.
The Four Pillars of Business Continuity
- Prevention (HA Focus)
- Redundant systems and fault tolerance
- Proactive monitoring and maintenance
- Security controls and access management
- Regular patching and updates
- Detection
- Automated monitoring of both HA and DR systems
- Alert mechanisms for component failures and anomalies
- Regular testing of failover procedures
- Continuous validation of backup integrity
- Response (DR Focus)
- Documented escalation procedures
- Clear decision trees for disaster declaration
- Designated recovery teams with defined roles
- Communication protocols for stakeholders
- Recovery
- Prioritized system restoration based on business impact
- Data validation and integrity checking
- Gradual failback to primary site when restored
- Post-incident review and improvement
Creating Your HA + DR Strategy
Follow this framework for comprehensive protection:
Step 1: Business Impact Analysis
- Identify critical systems and their RTO/RPO requirements
- Calculate actual costs of downtime per hour for each system
- Determine maximum tolerable downtime before business viability is threatened
- Document dependencies between systems
Step 2: Risk Assessment
- Evaluate likelihood and impact of various failure scenarios
- Separate component-level risks (HA domain) from site-level risks (DR domain)
- Consider both technical and business process risks
- Account for cyber threats, natural disasters, and human error
Step 3: Design HA Solutions
- Implement redundancy for components with single-point-of-failure
- Configure automatic failover for critical services
- Establish monitoring and alerting for proactive issue detection
- Test failover procedures regularly
Step 4: Design DR Solutions
- Select appropriate DR site model (cold/warm/hot) based on RTO/RPO requirements
- Implement backup strategies with offsite/offline copies
- Create detailed recovery procedures and runbooks
- Establish communication protocols for disaster scenarios
Step 5: Testing and Validation
- Schedule regular HA failover tests (quarterly minimum)
- Conduct annual full-scale DR exercises
- Document lessons learned and update procedures
- Verify that actual recovery times meet RTO targets
Common Pitfalls to Avoid
- Assuming HA Equals DR: The most dangerous mistake. Component redundancy doesn’t protect against site-wide disasters.
- Inadequate Testing: DR plans not tested are DR plans that won’t work. Schedule regular exercises.
- Ignoring Dependencies: Your database might recover in 30 minutes, but if the authentication system takes 4 hours, users can’t access anything.
- Unrealistic RTOs: Setting recovery targets that don’t match available technology and resources creates false confidence.
- Neglecting Runbooks: When disaster strikes, chaos reigns. Without detailed procedures, recovery times balloon.
Measuring Success: Key Metrics and Testing
Effective HA and DR strategies require continuous validation through metrics and testing.
HA Metrics
- System uptime percentage: Actual availability vs. target (99.9%, 99.99%, etc.)
- Mean time between failures (MTBF): Average operational time before component failure
- Mean time to recovery (MTTR): Average time from failure detection to service restoration
- Failover success rate: Percentage of automatic failovers completing successfully
- User-visible incidents: Number of outages that actually impacted users
DR Metrics
- Actual RTO vs. Target RTO: Are you meeting recovery time commitments?
- Actual RPO vs. Target RPO: Are you losing more data than acceptable?
- Test success rate: Percentage of DR tests meeting objectives
- Backup verification rate: Percentage of backups validated as restorable
- Recovery drill participation: Staff involvement in DR testing
Testing Methodologies
HA Testing:
- Quarterly controlled failover tests during maintenance windows
- Component failure simulation (pull network cables, power off servers)
- Load testing to validate system behavior under stress
- Chaos engineering approaches for production resilience
DR Testing:
- Annual full-scale disaster simulation with complete failover
- Quarterly tabletop exercises reviewing procedures without actual failover
- Monthly backup restoration validation
- Semi-annual recovery time measurement for critical systems
The Cost of Getting It Wrong
Organizations that neglect either HA or DR face severe consequences:
Financial Impact
Research by various industry analysts reveals:
- Average cost of IT downtime: $300,000 per hour (varies widely by industry)
- 60% of companies suffering major data loss shut down within 6 months
- Ransomware victims without backups pay an average of $1.85 million in combined ransom, recovery costs, and business disruption
- Cost of inadequate DR infrastructure is often 10-20x the cost of proper implementation
Operational Impact
Beyond direct financial costs:
- Loss of customer trust and brand reputation
- Regulatory penalties for service unavailability (especially in healthcare, finance)
- Employee productivity loss and morale damage
- Competitive disadvantage during extended outages
- Legal liability for service level agreement breaches
Conclusion: Complementary Strategies for Complete Protection
High availability and disaster recovery are not competing approaches – they are complementary layers of an integrated business continuity strategy. HA ensures business continuity in the face of everyday operational challenges, while DR ensures survival when things go catastrophically wrong.
For IT professionals responsible for business continuity, the question isn’t “HA or DR?” but rather “How can we optimize both to meet our specific RTO, RPO, and budget requirements?”
The complexity of modern IT infrastructure, coupled with the increasing sophistication of threats, from ransomware to natural disasters, requires a comprehensive approach:
- Implement high availability for mission-critical systems to eliminate single points of failure and minimize routine downtime.
- Create disaster recovery plans that address catastrophic scenarios in which the HA systems themselves become unavailable.
- Regularly test both systems to ensure they function when needed and meet actual business requirements.
- Document everything, because in the event of a disaster, chaos makes clear procedures invaluable.Review and update your infrastructure as new threats evolve and emerge.
The organizations that thrive aren’t those with perfect HA or flawless DR—they’re those that understand the difference, implement both appropriately, and continuously validate their effectiveness.
Ready to build a comprehensive business continuity strategy that integrates both high availability and disaster recovery? Storware Backup and Recovery provides enterprise-grade backup solutions that form the foundation of effective disaster recovery planning, working seamlessly alongside your high availability infrastructure. Our solutions support flexible RTO/RPO configurations, automated backup verification, and integration with both on-premises and cloud recovery sites—giving you the confidence that your data is protected regardless of what failures occur. Contact us to learn how Storware can help you bridge the gap between operational resilience and disaster preparedness.
