What is RAID and How Does it Work?
Table of contents
Hard drives fail. Not often, and not predictably — but they do, and usually at the worst possible moment. According to Backblaze’s 2024 Drive Stats report, the annualized failure rate (AFR) across a monitored fleet of over 300,000 HDDs was 1.57%. Scale that across a server room with dozens or hundreds of drives, and statistically, at least one drive failure per year is expected. RAID was designed to ensure that a single failed drive does not take your data with it.
This guide covers everything IT teams need to know about RAID: the correct definition, how the underlying mechanisms work, a practical comparison of all standard RAID levels, and — critically — where RAID ends and where backup must begin.

What Is RAID?
RAID stands for Redundant Array of Independent Disks. It is a technology that combines multiple physical drives — HDDs or SSDs — into a single logical unit, using specific techniques to improve performance, fault tolerance, or both.
The key word is independent. Each disk in a RAID array is a separate physical device. RAID software or hardware coordinates how data is distributed and replicated across them, so the array behaves as a single, reliable storage target from the perspective of the operating system and applications running above it.
RAID can be implemented in two ways:
- Hardware RAID — a dedicated RAID controller card (or onboard chipset) manages the array transparently from the OS. This offloads processing overhead and typically delivers the best performance.
- Software RAID — the OS kernel handles array management. Modern implementations in Linux (mdadm), Windows Storage Spaces, and ZFS are robust and widely used, though they consume CPU resources.
When drives are used individually without any RAID configuration, they are referred to as JBOD — Just a Bunch of Disks. Each drive appears as a separate logical device with no inherent redundancy.
How Does RAID Work?
All RAID levels are built on three core mechanisms, used in different combinations depending on the objective.
Striping
Data is split into fixed-size chunks called stripes and written across multiple drives simultaneously. This distributes I/O load and increases throughput — a single large sequential read or write can engage multiple drives in parallel. Stripe size is configurable and has a direct impact on performance profile: smaller stripes benefit workloads that read large files spanning many drives, while larger stripes suit high-concurrency environments where multiple users access independent records.
Mirroring
Identical copies of data are written to two or more drives simultaneously. If one drive fails, the mirror continues serving reads without interruption. Mirroring delivers strong fault tolerance and read performance — reads can be distributed across both copies — but the usable capacity is exactly half the raw total.
Parity
Parity is a calculated value derived from the data across drives in the array. If a single drive fails, its contents can be mathematically reconstructed from the remaining drives and the stored parity data. Parity-based RAID levels offer a middle ground: fault tolerance without the full storage overhead of mirroring. The trade-off is write performance — every write requires parity recalculation, which adds latency, particularly under random write workloads.
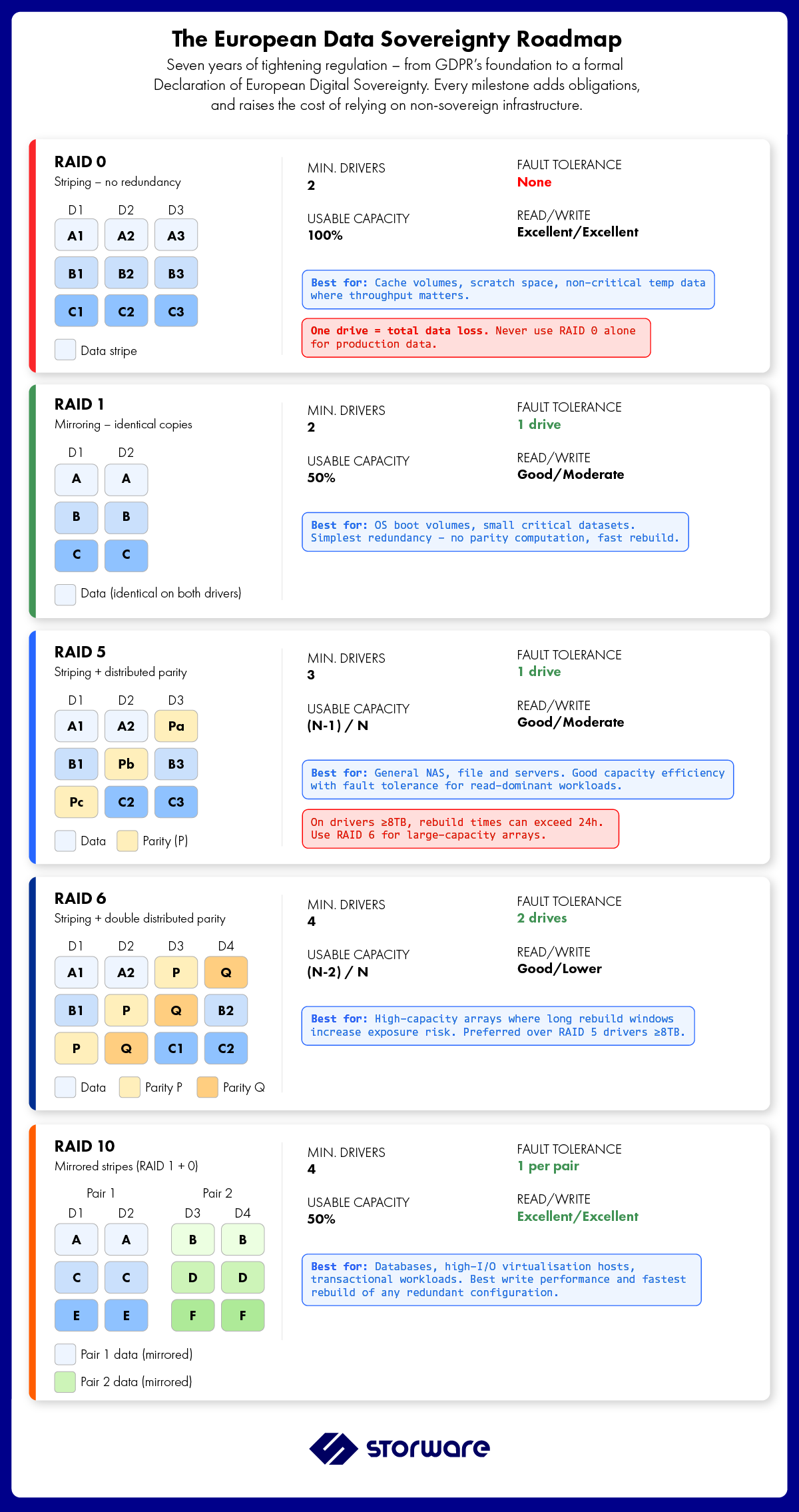
RAID Levels: A Practical Comparison
RAID levels are grouped into three categories: Standard, Nested, and Non-Standard. What follows covers the levels in regular production use. RAID 2, RAID 3, and RAID 4 are legacy designs that are effectively obsolete and not deployed in modern environments.
| RAID Level | Min. Drives | Fault Tolerance | Read Perf. | Write Perf. | Usable Capacity | Best For |
|---|---|---|---|---|---|---|
| RAID 0 | 2 | None | Excellent | Excellent | 100% | Scratch space, cache, non-critical data |
| RAID 1 | 2 | 1 drive | Good | Moderate | 50% | OS volumes, small critical datasets |
| RAID 5 | 3 | 1 drive | Good | Moderate | (N−1)/N | File servers, general-purpose storage |
| RAID 6 | 4 | 2 drives | Good | Lower | (N−2)/N | Large arrays, long rebuild scenarios |
| RAID 10 | 4 | 1 per mirror pair | Excellent | Excellent | 50% | Databases, high-I/O transactional workloads |
| RAID 50 | 6 | 1 per RAID 5 group | Very Good | Good | Variable | Enterprise file servers, large sequential workloads |
| RAID 60 | 8 | 2 per RAID 6 group | Very Good | Moderate | Variable | High-capacity archives, maximum resilience |
RAID 0 — Pure Striping
RAID 0 stripes data across all member drives with no redundancy whatsoever. The result is maximum read and write throughput — and zero fault tolerance. Lose one drive, lose everything. RAID 0 has legitimate use cases in temporary storage, caching layers, and environments where data is either disposable or fully protected elsewhere. It has no place as a primary storage layer for production data.
RAID 1 — Mirroring
RAID 1 writes identical data to two drives simultaneously. If one fails, the other continues without downtime. Read performance improves because the controller can service requests from either drive. Write performance incurs mild latency since both drives must confirm the write. The cost: 50% of raw capacity is consumed by the mirror. RAID 1 is the standard choice for OS boot volumes and small, business-critical datasets where simplicity and immediate failover matter more than capacity efficiency.
RAID 5 — Striping with Distributed Parity
RAID 5 distributes both data and parity across all member drives. There is no dedicated parity disk — parity is spread evenly, eliminating the write bottleneck present in the older RAID 4 design. The array can survive the loss of any single drive. Reads are fast; writes carry a parity computation overhead on every operation. RAID 5 remains the most commonly deployed configuration for general-purpose NAS and file server storage, offering a practical balance of capacity, performance, and fault tolerance with a minimum of three drives.
One important operational note: during a rebuild following a drive failure, RAID 5 reads every remaining drive to reconstruct the lost data. On large modern drives (16TB+), this rebuild window can take hours. A second drive failure during that window means total data loss — which is why RAID 6 is increasingly preferred for large-capacity arrays.
RAID 6 — Striping with Double Distributed Parity
RAID 6 extends RAID 5 by computing two independent parity blocks per stripe, enabling the array to survive two simultaneous drive failures. The write performance penalty is higher than RAID 5 due to the additional parity computation, and four drives are required as a minimum. For arrays using high-capacity drives (16TB and above) — where rebuild times are measured in days, not hours — RAID 6 is the operationally safer choice. The probability of a second failure during a multi-hour RAID 5 rebuild is not negligible when individual drive AFR is in the 1–2% range.
RAID 10 — Mirrored Stripes (RAID 1+0)
RAID 10 combines RAID 1’s mirroring with RAID 0’s striping. Data is written to mirrored pairs, and the pairs are striped together. The result is the highest write performance of any redundant RAID configuration, with fast rebuild times — only the mirror partner of the failed drive needs to be read during reconstruction, rather than the entire array. The trade-off is cost: 50% of raw capacity is consumed by mirroring regardless of array size. RAID 10 is the standard choice for database servers, high-I/O virtualization hosts, and any workload where write latency directly impacts application performance.
RAID 50 and RAID 60 — Enterprise Nested Levels
RAID 50 stripes data across multiple RAID 5 groups, improving throughput and fault tolerance compared to a single large RAID 5. Each RAID 5 group can sustain one drive failure independently. RAID 60 applies the same concept to RAID 6 groups, allowing two drive failures per group. Both configurations require a minimum of six (RAID 50) or eight (RAID 60) drives and are typically found in enterprise SAN environments and large-scale NAS deployments where performance and fault tolerance must scale together.
A Note on RAID-Z (ZFS)
Environments running ZFS — including many Linux KVM hosts, Proxmox clusters, and some Ceph configurations — use RAID-Z rather than traditional RAID levels. RAID-Z1, RAID-Z2, and RAID-Z3 correspond roughly to RAID 5, RAID 6, and triple-parity RAID, but with a fundamentally different parity implementation that eliminates the RAID 5 write hole (a data integrity risk during unclean shutdowns). If your storage layer runs on ZFS, understanding RAID-Z is more operationally relevant than traditional RAID level selection.
RAID in Modern All-Flash and Hybrid Environments
RAID was designed for spinning disks. In all-NVMe environments, the failure profile and performance characteristics shift significantly:
- SSDs and NVMe drives have substantially lower annualized failure rates than HDDs — but they fail differently, often without the early S.M.A.R.T. warning signals that spinning drives provide.
- Rebuild times are dramatically shorter on flash media, which reduces the exposure window for secondary failures during array reconstruction.
- In NVMe environments, software RAID overhead can become a meaningful factor. Dedicated hardware RAID controllers are worth evaluating for latency-sensitive workloads.
- Many modern all-flash arrays (AFAs) implement proprietary erasure coding rather than traditional RAID, offering better capacity efficiency and configurable protection levels.
The RAID level selection logic remains the same — the trade-offs between performance, capacity, and fault tolerance still apply — but the numbers change considerably compared to a traditional HDD array.
RAID Is Not a Backup
RAID protects against drive failure. It does not protect your data.
This distinction is the most important thing an IT architect or sysadmin can internalize about RAID. Consider what RAID cannot protect against:
- Ransomware — if the filesystem is encrypted, RAID faithfully replicates the encrypted data across all member drives. Every mirror, every stripe, every parity block reflects the corrupted state.
- Accidental deletion — a deleted file is deleted across the entire array immediately. There is no version history.
- Filesystem or controller corruption — logical corruption is not a physical drive failure. RAID provides no protection.
- Site-level events — fire, flooding, power surge, or theft. A RAID array is a single physical unit. Off-site or cloud-replicated backups are the only protection.
- Silent data corruption (bit rot) — traditional RAID levels do not detect or correct data corruption that occurs without a drive failure. ZFS is the notable exception, with built-in checksumming and self-healing.
RAID ensures storage availability in the event of a hardware failure. Backup ensures data recoverability in the event of any other failure — logical, human, or environmental. These are complementary disciplines, not alternatives to each other. An enterprise data protection strategy requires both.

For organizations running complex, heterogeneous environments — VMware vSphere, Proxmox, Nutanix AHV, Red Hat OpenStack, Hyper-V, or hybrid combinations — a dedicated backup solution that operates independently of the storage layer is essential. Storware Backup and Recovery is built precisely for this scenario: agentless, policy-driven protection across mixed hypervisor environments, with a single universal license covering all supported sources. RAID keeps your storage running; Storware ensures your data survives.
→ Speak with a Storware engineer about protecting the data on your RAID-backed infrastructure.
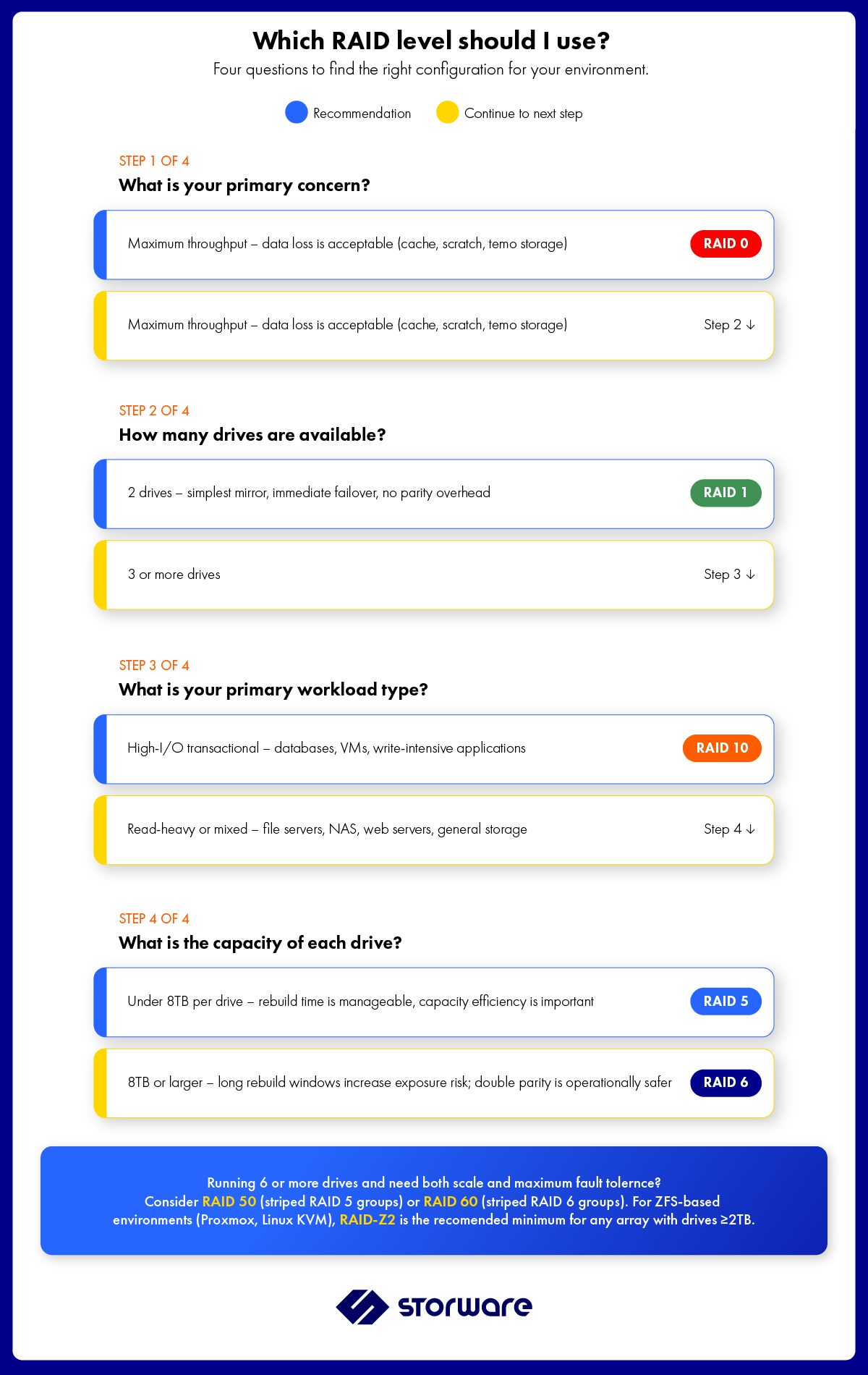
Choosing the Right RAID Level: A Practical Guide
The right RAID level depends on four factors: workload type, capacity requirements, fault tolerance requirements, and budget. A few practical rules of thumb:
- For OS volumes and boot drives: RAID 1. Simple, fast to rebuild, excellent availability.
- For general-purpose file and NAS storage with drives under 8TB: RAID 5. Good capacity efficiency, adequate fault tolerance.
- For high-capacity arrays with drives 10TB and above: RAID 6. The rebuild exposure window makes RAID 5 operationally risky at scale.
- For databases and high-I/O virtualization: RAID 10. Write performance and rebuild speed justify the 50% capacity cost.
- For large enterprise arrays requiring both scale and resilience: RAID 50 or RAID 60.
- For ZFS-based environments: RAID-Z2 as a minimum for any array containing drives larger than 2TB.
- Never use RAID 0 alone for data you cannot afford to lose.
Frequently Asked Questions
What does RAID stand for?
RAID stands for Redundant Array of Independent Disks. An earlier formulation used “Inexpensive” rather than “Independent,” but the modern standard is Independent. RAID combines multiple physical drives into a single logical storage unit using techniques like striping, mirroring, and parity to improve performance, fault tolerance, or both.
Is RAID a backup?
No. RAID is a high-availability technology for storage hardware — it protects against drive failure. It does not protect against ransomware, accidental deletion, logical corruption, or site-level disaster. A separate, dedicated backup solution is required to ensure data recoverability in these scenarios. The industry standard rule is the 3-2-1 rule: three copies of data, on two different media types, with one copy stored off-site.
What is the difference between RAID 5 and RAID 6?
RAID 5 uses single distributed parity, tolerating one drive failure. RAID 6 uses double distributed parity, tolerating two simultaneous failures. RAID 6 requires a minimum of four drives (versus three for RAID 5) and has a higher write overhead due to computing two parity values. For arrays using modern high-capacity drives where rebuild times can exceed 24 hours, RAID 6 is the safer choice — the probability of a second failure during a lengthy RAID 5 rebuild is not negligible.
Which RAID level is best for a server?
There is no single answer — it depends on the workload. General-purpose file servers commonly use RAID 5 or RAID 6. Database and high-I/O servers typically use RAID 10. Storage arrays prioritizing maximum fault tolerance at scale use RAID 50 or RAID 60. The most important principle is to match the RAID level to the workload’s I/O profile and to ensure the chosen level’s fault tolerance meets the operational risk tolerance of the business.
What is the difference between hardware RAID and software RAID?
Hardware RAID uses a dedicated controller card or onboard chipset to manage the array, offloading parity computation from the host CPU. Software RAID uses the OS kernel — Linux mdadm, Windows Storage Spaces, or ZFS — with the host CPU handling all RAID operations. Modern software RAID implementations are mature and suitable for most workloads. Hardware RAID is worth evaluating for latency-sensitive environments where consistent microsecond-level I/O is required.
Can RAID recover from ransomware?
No. Ransomware encrypts files at the filesystem level, not at the drive level. RAID replicates this encrypted state faithfully across all member drives. By the time the attack is detected, every mirror and every parity stripe reflects the compromised data. Recovery from ransomware requires an isolated, deduplicated backup copy that predates the encryption event — exactly what a purpose-built backup solution provides.
What is RAID-Z?
RAID-Z is ZFS’s native implementation of parity-based redundancy. RAID-Z1 (single parity), RAID-Z2 (double parity), and RAID-Z3 (triple parity) correspond roughly to RAID 5, RAID 6, and triple-parity RAID, but with one key advantage: ZFS checksums every data block and can detect and correct silent corruption, which traditional RAID cannot. RAID-Z is the standard choice for ZFS-based storage environments, including many Proxmox and Linux KVM deployments.
Storware Backup and Recovery is a proven, agentless data protection platform designed for complex enterprise environments — covering VMware vSphere, Proxmox, Nutanix AHV, Red Hat OpenStack, Hyper-V, and more under a single universal license. Book a meeting with our team to discuss your backup architecture.
